{kind=link}
 智能投顾和AI,目前在金融领域的应用到了哪种程度?
智能投顾和AI,目前在金融领域的应用到了哪种程度?
人工智能顾问最大的亮点就体现在这了,它可以以很少的费用甚至免费为散户投资者提供一个合理的综合建议,这是因为开发智能投顾的成本远低于聘用注册投顾的薪水开支。


过去我们用通过编写设定程序来直接让计算机完成某些特定任务,现在,我们还可以训练计算机,就像我们训练宠物一样。这就是用大白话来解释机器学习。当然了,对于一些相对简单的任务我们还是在通过编写程序来让计算机直接去执行,以后也还会继续下去。但是有些任务实在太太太复杂,通过编程来计算机直接执行来实现是不可能的。
举个简单的例子,一个软件工程师,被分配去开发一个可以用来检测输入图像中的猫的计算机软件。通过编程硬来让计算机做到这一点是不可能的,因为识别图像是一个极其复杂的任务。一个图像是由一块块小小的像素组成(极低的像素也有300 x 300,也就是9万块像素),而每个像素里有不同色彩,色彩强度值又可以从0到1000。要想通过编程来确定哪些图片里有猫就意味着要考虑每块像素的色彩及强度,并且考虑到各种图片里猫咪出现的不同情况(猫的颜色,大小,形状,姿势,出现在图片中的位置,背景情况*#§$%&......),很明了,想要把所有可能的组合考虑到并把对应程序编写出来一辈子的时间也不够。这时候你就需要使用机器学习了,也就是说,你需要训练这个软件,来自行执行任务。
机器学习系统(或可训练软件)有内部模型参数,在学习过程中这些参数可以基于不同数据而被不断优化。回到上面提到过的识别猫图片的任务,需要做的是,首先针对这个任务我们选择一个最合适的模型;然后给这个系统导入许多已标识的图片(有猫的图片自带标记1,没有猫的图片自带标记0);在一遍又一遍地导入不同图片的过程中,机器学习系统也会一遍又一遍地调整系统模型参数——也就是机器学习过程(或者说我们训练机器的过程)。最后结果就是当它学习好的时候,我们导入未标识的图像,这个训练“出师”的软件就可以根据之前学习得到的模型参数直接识别出图像里有没有或者是不是猫咪了。
这个例子只是机器学习应用中的一个分支,今天我们来了解一下机器学习里的三大类型:有监督、无监督、强化学习。

设想一个小孩看到了许多不同的动物,小孩的爸爸会告诉他哪种动物是狗...在爸爸给过小孩几次提示之后,小孩又看到了一种从未见过的狗,但是小孩还是识别出那是只狗,而不是猫,或者猴子,或者石头。这个例子就是监督机器学习算法的分类识别应用。在这个算法里,会有“老师”指导机器学习概念。这样,当一个新的样本出现的时候,就算在机器的数据库里没有出现过,还是可以被识别出来。

这类算法是对给定样本集上的模式进行预测和搜索的算法。有监督的机器学习算法会在目标预测输出和输入特征之间寻找并建立依赖关系,这个关系则可以用于针对不同输入值(X)进行未知输出值(Y)的预测。
在监督学习类别下,有一些常见的应用,如线性回归、随机森林、支持向量机、最近邻等。监督学习常用在的一下两个问题上:
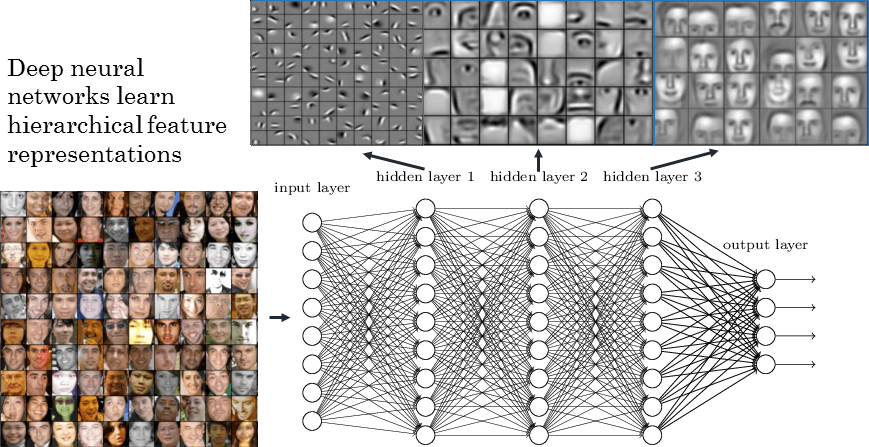
监督机器学习的一个著名成果是通过卷积神经网络(CNN)进行面部识别。
再来设想你准备要去一个新的环境,一个从没去过的国家生活,虽然你对当地的一切都一无所知,但是从到了的第一天开始,通过你自己各种不同的尝试——学习吃当地的饮食,学习怎么去海滩,学习用什么语言交流等等,你慢慢开始了就心里有数了。这是无监督机器学习的例子——当你有大量的信息但又不知道怎么用这些信息的情况。和监督机器学习根本不同在于,没有“老师”来指导你,你必须自己找出路,根据一些标准把这些信息转化成对你有意义的群体,在这个例子里无监督机器学习就可以理解成你最后将所得信息分成衣、食、住、行、文化等类别,并找到各个类别里当地人遵循的规则的过程。
稍微学术点再解释一下,这类机器学习就是将数据安排成组簇,并对各组簇的结构进行描述,使复杂的数据看起来简单而有组织,以便于分析利用。无监督学习是在没有标记数据的情况下进行的,也就是说只输入数据而没有一致的输出参数。这类机器学习主要用于解决为寻找固有关联关系的聚类问题。一些非监督学习的流行例子有:

上图是大数据可视化图例——2017年的全球恐袭地图分布,由ArcGIS的研发公司美国环境系统研究所公司(Environmental Systems Research Institute, Inc.,简称Esri)发布。附带连接应用连接: Annual Terrorist Attacks
强化学习是人工智能中最活跃的研究领域之一。强化学习就是奖惩训练。我们像训练宠物一样训练机器——如果宠物服从和按照我们的指示行事,我们会通过给它饼干来奖赏它,反之则惩罚。同样,如果系统运作良好,那么我们会给出代表肯定意义的数值(即奖励),反之则给予否定意义的数值(即惩罚)。得到惩罚的学习系统必须改进自己。因此,这是一个反复试验的过程(迭代), 这类算法根据数据点做出行动,并会对这个决策做出评估。随着时间的推移,最终强化学习算法会有选择地保留最有可能接收到的奖励的那些输出结果。
常见的强化学习有Q-学习、深对抗网络和时间差异。算法适用于游戏AI、技能学习、任务学习、机器人导航和实时决策等领域。一个著名的强化学习演示就发生在2017年5月在乌镇举行的DeepMind的AlphaGo AI程序与柯洁之间的围棋比赛上,人工智能连续三盘打败了世界排名第一的围棋手。柯洁在最后的采访中对人工智能评价道:“没有想到人工智能已经进化到这种程度了,它们的自主学习能力太强大,未来真的是属于人工智能技术了。”
在机器学习过程中输入的用来训练机器的数据量越大,最后这个系统得出的结果就越精确。这也就是为什么大数据这个概念总是会与人工智能、机器学习一起出现的原因了,因为没有大数据作为基础,就没有办法训练机器,也就没有智能一说了。我们现在刚好处在大数据爆发的年代,互联网科技使得越来越多的信息数字化,以后还会有更多的数据,这也就为将来机器学习、人工智能的进一步发展提供了原料。在未来几年中,机器学习一定还会继续取代世界各地的大量工作。 该如何利用机器学习还有人工智能来准备面对其带来的浪潮,是每一个作为公司管理者,决策者,参谋人都应该思考的。
 智能投顾和AI,目前在金融领域的应用到了哪种程度?
智能投顾和AI,目前在金融领域的应用到了哪种程度?
 人工智能系列(一)请为人工智能浪潮做好准备
人工智能系列(一)请为人工智能浪潮做好准备